面向AI的多模态数据治理(框架篇)
作者:信息网络中心 时间:2026-04-14 点击数:
1. 数据治理对比
以“传统结构化”与“大模型多模态”为双轴,构建21项核心差异对比框架。从治理对象(固定Schema vs 异构多模态)、元数据管理(技术/业务元数据 vs 多模态/语义元数据)、管控抓手(主数据/规则引擎 vs 语义对齐/事实校验)三大维度切入,明确多模态治理以“语义适配”“知识密度”“AI价值观对齐”为核心,解决传统治理在无结构数据场景下的能力失效问题,为多模态治理体系奠定差异化定位基础。
一级对比维度 |
二级细分项 |
传统结构化数据治理 |
面向大模型的多模态数据治理 |
一、核心治理维度 |
核心治理对象 |
有固定 Schema 的二维关系型数据(库、表、字段、视图),核心为主数据、参考数据、交易数据,结构显性化、可枚举、边界清晰 |
无固定 Schema 的多模态异构数据(长文本、图像、音频、视频、代码、图表、3D 点云等),语义深度隐含、模态间差异极大、无统一结构边界 |
|
元数据管理核心 |
围绕技术元数据、业务元数据、管理元数据展开,核心管控库 - 表 - 字段的血缘、属性、权限,强 Schema 约束,元数据静态稳定 |
围绕多模态元数据、语义元数据、模型适配元数据展开,核心管控模态 - 知识域 - 向量特征 - 模型训练 / 推理全链路血缘,弱 Schema 约束,元数据随模型迭代动态更新 |
|
核心管控抓手 |
主数据管理、数据模型管控、数据标准落地、业务规则引擎,以 结构与业务规则 为核心管控抓手 |
跨模态语义对齐、知识密度管控、事实一致性校验、AI 价值观对齐,以 语义与模型适配 为核心管控抓手 |
|
数据质量管理核心 |
聚焦数据的格式、值域、完整性、一致性等 结构级质量 ,解决数据不标准、不一致、孤岛化问题 |
聚焦数据的知识密度、事实准确性、跨模态匹配度等 语义级质量 ,解决大模型幻觉、偏见、能力短板、安全风险问题 |
|
安全合规治理核心 |
聚焦 字段级显性敏感信息 管控,核心解决个人信息泄露、权限越权、数据跨境等合规风险 |
聚焦 全链路隐性合规风险 管控,除基础数据安全外,核心解决版权侵权、肖像权 / 知识产权侵犯、有害内容、隐性偏见、生成内容次生合规风险 |
|
生命周期管理核心 |
与业务系统生命周期绑定,按业务与监管要求做全周期留存管理,周期长、变更频率低、稳定可预测 |
与大模型迭代周期强绑定,按预训练 / 微调 / RAG 等模型场景分级管理,迭代速度快、更新频率高,与模型版本强关联、可追溯 |
二、治理标准和要求 |
核心质量标准体系 |
经典 6 维度标准: 准确性、完整性、一致性、唯一性、及时性、有效性 ,对错边界清晰,可 100% 量化、可枚举、可全覆盖校验 |
核心 8 维度标准: 事实一致性、跨模态对齐度、知识密度、内容多样性、无毒性、无偏见、泛化性、合规性 ,以语义级评估为主,边界动态模糊,需 AI 模型深度打分校验 |
|
合规管控标准 |
以《数据安全法》《个保法》及行业监管规范为核心,标准固定、落地路径成熟、可通过固定规则实现全量自动化校验 |
除基础法律法规外,新增版权法、知识产权、AIGC 行业规范、模型安全对齐标准等,标准动态更新,风险识别需多模态 AI 能力,无通用固定规则 |
|
数据标准化要求 |
强统一标准,要求数据格式、编码、值域、命名规范完全统一,以 “同构同质” 为核心目标 |
弱格式标准,强语义标准,不要求结构统一,核心要求跨模态语义统一、知识表述对齐、价值观标准统一,以 “同义同质” 为核心目标 |
|
评估校验规则 |
以 确定性规则校验 为核心,通过 SQL、规则引擎实现自动化校验,一次规则配置可长期复用,无需频繁迭代 |
以 模型化语义评估 为核心,通过大模型打分、多模态模型校验、人工标注反馈结合的方式实现,规则随模型效果反馈持续迭代优化 |
|
迭代更新要求 |
标准随业务架构、监管要求变更而更新,迭代周期长、版本稳定,无高频迭代需求 |
标准随大模型技术迭代、场景拓展、安全风险变化持续更新,与模型训练 / 推理效果形成闭环,高频迭代是常态 |
三、技术体系 |
核心技术逻辑 |
业务规则驱动、强 Schema 约束,采用线性、标准化、可复刻的批处理 / 流处理逻辑,治理与业务流程解耦 |
语义与 AI 模型驱动、弱 Schema / 无 Schema,采用与模型迭代强绑定的闭环迭代式处理逻辑,治理与模型全流程深度耦合 |
|
核心处理引擎 |
ETL/ELT 引擎、SQL 引擎、批流处理引擎(Spark/Flink)、业务规则引擎、数据质量稽核引擎 |
多模态嵌入引擎、大模型语义理解 / 打分引擎、跨模态语义对齐引擎、内容安全审核引擎、向量检索引擎、数据合成增强引擎 |
|
核心工具组件 |
关系型数据库、数据仓库 / 数据湖、主数据管理平台、元数据管理平台、数据脱敏工具、数据血缘分析工具 |
向量数据库、多模态内容解析工具、大模型数据过滤 / 清洗平台、多模态去重 / 去噪工具、AI 对齐训练平台、AIGC 内容溯源工具 |
|
核心存储体系 |
以结构化存储为核心,集中式数仓、分布式数据湖、关系型数据库为主体,按库 - 表 - 字段分层存储 |
以多模态异构存储为核心,对象存储 + 向量数据库为主体,搭配分布式文件存储,按模态、知识域、质量等级、适配模型场景分级存储 |
|
算力依赖特征 |
以 CPU 算力为主,算力需求稳定,峰值可控,无大规模 AI 算力依赖 |
以 GPU/NPU 等 AI 算力为核心,算力需求大,与模型训练 / 推理任务强绑定,峰值算力需求极高,依赖分布式 AI 算力集群 |
四、业务体系 |
核心治理目标 |
保障数据的标准化、一致性、合规性,破解数据孤岛问题,支撑确定性业务决策、交易核算、监管合规,实现数据资产化 |
提升大模型的生成质量、事实一致性、安全性、泛化能力,根治幻觉、偏见、合规风险,支撑生成式 AI 全生命周期落地,直接决定企业 AI 核心能力上限 |
|
核心落地场景 |
企业 ERP/CRM 等核心业务系统、数据仓库 / 数据湖建设、BI 经营分析、监管报送、交易核算、财务对账、主数据统一 |
通用大模型预训练语料构建、行业大模型微调数据集制作、RAG 知识库治理、多模态生成内容管控、AI 安全与价值观对齐、企业知识图谱构建 |
|
流程耦合特性 |
治理流程与业务系统解耦,独立于业务流程运行,一次治理完成的数据可长期复用,无强耦合的闭环要求 |
治理流程与大模型训练 / 推理全流程强耦合,形成 “数据治理→模型训练→效果反馈→优化治理” 的持续闭环,治理与模型迭代同步推进 |
|
组织与人才要求 |
核心团队为数据治理工程师、数据架构师、DBA、业务分析师、合规专员,核心能力为数据建模、SQL 开发、业务流程梳理、合规管控 |
核心团队为数据治理工程师、多模态算法工程师、NLP 工程师、AI 安全工程师、版权合规专家,核心能力为大模型技术、多模态语义处理、AI 安全管控、版权合规 |
|
价值量化与落地路径 |
价值通过业务效率提升、合规成本降低、数据资产复用率提升量化,落地路径为 “标准制定→规则落地→质量稽核→持续优化”,线性推进 |
价值通过模型性能提升、幻觉率降低、用户满意度提升、合规风险下降量化,落地路径为 “数据筛选→清洗增强→模型验证→效果反馈→策略迭代”,闭环滚动推进 |
2. 技术体系
搭建“算力-解析-治理-融合-模型-运维”6层技术架构,形成多模态治理的完整技术闭环。基础层以GPU集群+向量数据库解决PB级存储与检索难题;解析层通过OCR/ASR引擎实现异构数据“可读化”转换;核心治理层聚焦去重/过滤/事实校验三大质量管控技术;最终通过模型适配与运维层实现治理策略的自动化迭代,确保技术体系既满足当前数据清洗需求,又支撑大模型全生命周期的动态适配。
技术层级 |
核心技术组件 |
核心技术能力 |
核心治理目标 |
基础算力与存储层 |
分布式 AI 算力集群(GPU/NPU)、对象存储、分布式文件系统、向量数据库、高速网络架构 |
多模态海量数据的分布式存储、高并发算力调度、向量数据的高效检索与管理、多模态数据的统一纳管 |
为全流程多模态治理提供稳定、可扩展的算力与存储底座,支撑 TB/PB 级多模态数据的并行处理 |
多模态解析与预处理层 |
多模态格式解析引擎、OCR 图文识别引擎、ASR 语音转写引擎、视频抽帧 / 关键信息提取引擎、文档结构化解析引擎、代码语法解析引擎 |
异构多模态数据的统一接入、格式转换、非结构化数据的结构化解析、关键信息提取、噪声信号过滤、基础格式标准化 |
解决多模态数据的 “可读” 问题,将异构数据转化为可被模型与治理引擎理解的标准化语义单元 |
核心数据治理技术层 |
多模态精准去重技术、低质数据过滤技术、多语种分词与清洗技术、知识密度评估技术、事实一致性校验技术、数据去重 / 去噪技术 |
海量多模态数据的批量清洗、重复数据识别与剔除、低质 / 垃圾数据过滤、虚假信息识别、知识密度分级、数据规范化处理 |
解决多模态数据的 “干净度” 问题,剔除无效、低质、错误数据,保障治理后数据的基础质量 |
语义增强与对齐技术层 |
多模态嵌入(Embedding)技术、跨模态语义对齐技术、知识图谱融合技术、指令微调格式化技术、数据合成与增强技术、领域知识蒸馏技术 |
跨模态数据的语义统一表征、图文 / 音视频等跨模态内容一致性校验、领域知识增强、高质量样本合成、指令数据标准化、语义单元的关联与映射 |
解决多模态数据的 “可用性” 问题,提升数据的知识密度、语义一致性、领域适配性,匹配大模型训练与推理的语义要求 |
模型适配与闭环优化技术层 |
大模型打分与评估技术、训练 / 推理效果反馈技术、数据 - 模型血缘追踪技术、自动化 A/B 测试技术、模型性能归因分析技术 |
治理后数据的模型适配性验证、模型效果与数据质量的关联分析、治理策略的自动化迭代、数据全链路血缘追踪、模型短板的靶向数据优化 |
实现 “数据治理→模型训练→效果反馈→治理优化” 的闭环,让数据治理持续匹配模型迭代需求,精准提升模型能力 |
安全合规与风险管控技术层 |
多模态内容安全审核技术、敏感信息识别与脱敏技术、版权溯源与侵权检测技术、偏见与有害内容识别技术、模型价值观对齐技术、AIGC 内容溯源技术 |
多模态数据的全链路安全审核、个人信息 / 敏感内容脱敏、版权合规校验、隐性偏见与有害内容识别剔除、生成内容的合规管控、数据合规性全流程审计 |
解决多模态数据的 “安全性” 问题,防控全链路合规风险,保障大模型的内容安全与价值观对齐,规避法律与舆情风险 |
3. 业务体系
围绕大模型“预训练-微调-RAG-生成-安全-运营”6大核心业务域,构建场景化治理矩阵。预训练域聚焦大规模语料合规性与多样性,微调域强调指令对齐与偏好优化,RAG域解决知识精准性与实时性,安全域管控价值观对齐与风险拦截,最终通过资产运营域实现数据从“治理成果”到“可复用资产”的转化,确保每个业务域的治理目标与大模型生命周期环节深度绑定,避免治理与业务脱节。
业务域 |
核心业务场景 |
核心治理目标 |
核心输出成果 |
适配大模型全生命周期环节 |
预训练语料治理业务域 |
通用语料采集与清洗、领域预训练语料构建、多模态预训练语料对齐、语料质量分级与筛选、预训练语料合规审核 |
构建大规模、高质量、多元化、合规的预训练语料库,保障基础模型的通用能力、知识广度与基础安全 |
分级分类的预训练语料库、语料质量评估报告、语料合规审计报告、预训练语料元数据台账 |
大模型预训练阶段、继续预训练阶段 |
微调数据集治理业务域 |
监督微调(SFT)数据集构建、偏好对齐(RLHF/DPO)数据集制作、领域指令数据集治理、多模态指令微调数据对齐、小样本场景数据集优化 |
构建高质量、高对齐度、强领域适配性的微调数据集,精准提升模型的领域能力、指令遵循能力、人类价值观对齐能力 |
标准化微调数据集、指令模板库、偏好对齐样本库、数据集质量评估报告、微调效果验证报告 |
大模型监督微调阶段、偏好对齐与 RLHF 阶段、领域适配微调阶段 |
RAG 知识库治理业务域 |
企业私域知识库解析与结构化、知识切片与向量化优化、知识库事实一致性校验、知识更新与版本管理、多模态知识库语义对齐、检索精度优化 |
构建高精准、高可用、实时更新的 RAG 知识库,根治大模型推理阶段的幻觉问题,提升私域知识问答的准确率与相关性 |
标准化 RAG 知识库、知识切片库、向量索引库、知识元数据台账、知识库更新与运维规范、问答效果验证报告 |
大模型推理服务阶段、RAG 检索增强生成场景、私域知识问答场景 |
多模态生成内容治理业务域 |
生成内容的事实一致性校验、生成内容合规审核、多模态生成内容版权校验、生成内容偏见与有害信息识别、生成内容质量分级、AIGC 内容溯源与水印管理 |
管控大模型多模态生成内容的质量、合规性与安全性,规避生成内容带来的舆情、法律、合规风险,保障用户体验 |
生成内容安全审核规则库、多模态内容质量评估模型、AIGC 内容溯源体系、生成内容合规审计报告、风险处置台账 |
大模型推理服务阶段、多模态生成场景、对外服务输出环节 |
AI 安全与对齐治理业务域 |
有害数据识别与剔除、偏见数据筛查与治理、越狱风险数据防控、敏感信息脱敏与管控、模型价值观对齐数据构建、红队对抗测试数据集治理 |
构建全链路的 AI 安全治理体系,防控大模型的安全风险,保障模型的价值观与监管要求对齐,规避越狱、有害生成等安全问题 |
安全对齐样本库、有害内容特征库、风险防控规则库、安全合规审计报告、红队对抗测试报告、模型安全评估报告 |
大模型预训练 / 微调全流程、模型安全对齐阶段、上线前安全测评阶段 |
多模态数据资产运营业务域 |
多模态数据资产分级分类、数据资产全生命周期管理、数据资产血缘追踪、数据资产合规与授权管理、数据资产复用与共享、数据资产价值评估 |
实现多模态数据的资产化管理,建立可追溯、可复用、可管控的数据资产体系,提升数据资产的复用率与商业价值 |
多模态数据资产目录、数据资产分级分类标准、数据资产授权管理体系、数据资产价值评估模型、数据资产运营台账 |
全生命周期全场景,覆盖数据采集、治理、应用、归档全流程 |
4. 功能体系
设计8大核心功能模块,形成“接入-清洗-评估-对齐-合规-管理-运营-优化”的全流程治理能力。接入层实现多源异构数据统一纳管,清洗层解决数据“干净度”问题,对齐层通过语义嵌入实现跨模态关联,合规层构建全维度安全审核机制,最终通过模型适配模块形成“治理效果-模型反馈-策略迭代”的闭环,确保功能体系既覆盖基础治理需求,又具备支撑大模型动态优化的高阶能力。
功能模块 |
核心功能点 |
核心操作能力 |
核心输出成果 |
多模态数据接入与解析模块 |
多源异构数据统一接入、多格式数据自动解析、非结构化数据结构化提取、批量数据同步与增量更新 |
支持文本 / 图像 / 音频 / 视频 / 文档 / 代码等全模态数据接入,支持本地 / 云端 / API 多源接入,OCR/ASR/ 视频关键信息提取、文档结构化解析、批量数据同步调度 |
标准化解析后的语义单元、结构化提取结果、数据接入台账、解析任务执行日志 |
数据清洗与去重模块 |
多模态数据批量清洗、精准去重与近重识别、低质 / 垃圾数据过滤、空值 / 噪声数据剔除、格式规范化处理 |
支持海量数据的分布式并行清洗、基于语义的精准去重 / 近重识别、低质数据自动打分与过滤、自定义清洗规则配置、批量清洗任务调度 |
清洗后的高质量数据集、去重 / 过滤明细台账、数据清洗质量报告、清洗规则模板库 |
质量评估与分级模块 |
多维度数据质量自动打分、数据质量规则自定义、数据分级分类管理、质量问题溯源与标注、质量报告自动生成 |
支持事实一致性、知识密度、合规性等多维度自动评估、自定义质量阈值配置、数据自动分级打标、质量问题可视化溯源、批量质量稽核 |
数据质量分级标签、数据质量评估报告、质量问题明细台账、质量规则库、数据质量仪表盘 |
语义对齐与知识增强模块 |
多模态语义嵌入与表征、跨模态语义一致性校验、知识切片与向量化优化、知识图谱融合与关联、数据合成与增强、指令格式化处理 |
支持跨模态语义对齐校验、自定义知识切片规则、领域知识增强、高质量样本合成、指令模板标准化、批量向量化处理 |
语义对齐后的多模态数据集、知识切片库、向量索引库、指令模板库、合成增强样本集、语义对齐校验报告 |
安全合规与审核模块 |
多模态内容安全审核、敏感信息识别与脱敏、版权溯源与侵权检测、偏见与有害内容识别、合规规则自定义、风险处置与审计 |
支持全模态内容批量安全审核、敏感信息自动脱敏、版权内容自动识别、有害内容自动拦截、自定义合规规则配置、全流程合规审计留痕 |
内容安全审核报告、脱敏后的合规数据集、合规风险台账、风险处置记录、合规审计日志、安全规则库 |
元数据与血缘管理模块 |
多模态元数据全生命周期管理、数据 - 模型全链路血缘追踪、元数据自动采集与更新、数据资产目录管理、数据版本管理 |
支持多模态元数据自动采集与维护、数据全链路血缘可视化追踪、数据资产自动编目、数据版本全生命周期管理、元数据检索与查询 |
多模态元数据台账、全链路血缘图谱、数据资产目录、数据版本管理台账、元数据变更日志 |
资产运营与管理模块 |
数据资产分级分类管理、资产授权与共享管理、资产价值评估、资产复用与订阅管理、资产合规与归档管理 |
支持数据资产自定义分级分类、细粒度的资产授权管控、资产价值量化评估、资产共享与订阅调度、资产归档与销毁全流程管理 |
数据资产分级分类台账、资产授权管理体系、资产价值评估报告、资产共享与订阅记录、资产归档台账 |
模型适配与闭环优化模块 |
模型效果反馈与归因分析、治理策略自动化迭代、数据 - 模型效果关联分析、自动化 A/B 测试、模型短板靶向数据优化 |
支持模型生成效果自动采集与分析、数据质量与模型效果关联归因、治理策略自动优化迭代、自动化 A/B 测试调度、靶向数据筛选与增强 |
模型效果评估报告、治理策略优化方案、靶向优化数据集、A/B 测试报告、策略迭代日志 |
5. 数据体系
按“文本-图像-音频-视频-融合-结构化转知识”6大模态分类,建立差异化治理框架。文本模态聚焦知识密度与事实校验,图像/音频/视频模态重点管控版权风险与内容安全,融合模态核心解决跨模态语义一致性,结构化转知识模态则实现业务数据向模型可理解语义的转化,每个模态均明确“特征-要点-场景”三维管控标准,避免多模态治理“一刀切”,确保治理策略与模态特性精准匹配。
数据大类 |
模态细分 |
核心数据特征 |
核心治理要点 |
典型应用场景 |
文本类数据 |
通用网页文本、书籍文献、行业白皮书、政策法规、企业文档、问答数据、对话日志、指令数据、代码文本、新闻资讯 |
大模型最核心的基础数据,知识密度差异大、质量参差不齐、存在大量低质 / 虚假 / 侵权内容,语义深度隐含,是模型语言能力与知识能力的核心载体 |
低质内容过滤、精准去重 / 近重去重、事实一致性校验、知识密度分级、敏感信息脱敏、版权合规校验、指令格式化、语种规范化 |
预训练语料构建、SFT 微调数据集制作、RAG 知识库建设、指令对齐训练 |
图像类数据 |
摄影图片、设计素材、图表图谱、表情包、产品图片、医疗影像、遥感影像、3D 渲染图、生成式图片 |
无固定结构,语义信息隐含在视觉特征中,版权风险极高,存在大量有害、低俗、侵权内容,需与文本语义强关联 |
版权溯源与侵权检测、内容安全审核、有害内容剔除、图文一致性校验、去重与低质过滤、分辨率与格式标准化、敏感信息脱敏 |
多模态预训练、图文对齐微调、文生图 / 图生文场景、多模态 RAG、视觉问答场景 |
音频类数据 |
语音对话、有声书、音乐音频、广播节目、访谈录音、会议音频、环境音、ASR 转写文本 |
时序类数据,语义信息需通过转写提取,存在口音、噪声、多语种混杂问题,肖像权 / 版权风险高,敏感信息隐蔽 |
噪声过滤、语音转写与文本对齐、敏感语音识别与脱敏、版权合规校验、低质音频过滤、语种与口音规范化、内容安全审核 |
语音大模型预训练、语音指令微调、语音对话场景、音频内容理解、语音 RAG 场景 |
视频类数据 |
短视频、长视频、课程视频、直播回放、监控视频、影视素材、动画视频、演示视频 |
融合图像、音频、文本、时序信息的复合模态,数据体量大、语义信息分散、处理复杂度高,版权 / 肖像权风险极高,合规管控难度大 |
关键帧提取与内容解析、音视频文本对齐、内容安全审核、版权与肖像权校验、低质 / 无效片段过滤、跨模态语义一致性校验、敏感信息脱敏 |
多模态大模型预训练、视频理解微调、文生视频 / 视频问答场景、视频内容检索、多模态 RAG |
多模态融合数据 |
图文配对数据、音视频字幕配对数据、文档图文混合数据、对话多轮多模态数据、指令 - 回答多模态配对数据 |
跨模态语义强关联,是多模态大模型对齐训练的核心数据,核心风险为跨模态语义不匹配、配对错误、信息不一致 |
跨模态语义一致性校验、配对准确性审核、低质配对数据剔除、语义对齐优化、格式标准化、合规性全维度审核 |
多模态预训练、图文 / 音视频对齐微调、多模态指令跟随训练、多模态生成场景 |
结构化转知识数据 |
关系型数据库表数据、主数据、指标数据、业务交易数据、Excel 表格数据、API 结构化返回数据 |
有固定 Schema,事实准确性高、业务属性强,是行业大模型的核心领域数据,需转化为模型可理解的语义知识 |
语义化转换、知识图谱构建、事实一致性校验、业务语义标注、敏感字段脱敏、增量更新与版本管理、指令化格式化 |
行业大模型微调、RAG 业务知识库建设、指标与业务问答场景、企业内部业务系统对接 |
6. 数据层级
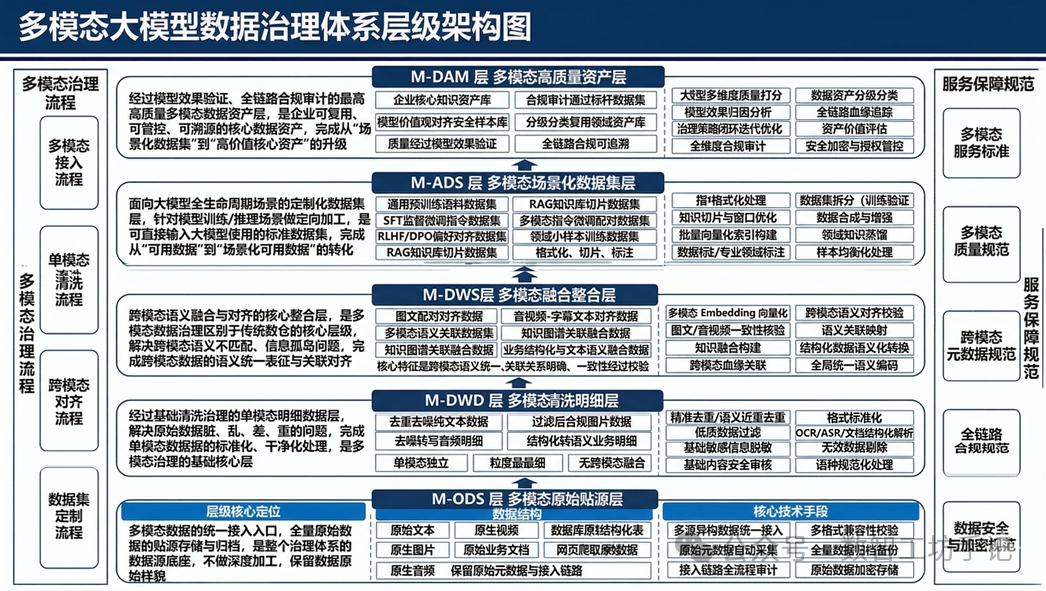
构建“原始贴源-清洗明细-融合整合-场景化数据-高质量资产”5层数据架构,实现数据价值阶梯式提升。M-ODS层保留原始数据用于溯源,M-DWD层解决单模态数据质量问题,M-DWS层实现跨模态语义统一,M-ADS层输出模型可用的场景化数据集,最终在M-DAM层形成可复用、可管控的核心资产,每层均明确技术手段与适用场景,确保数据从接入到资产化的全链路可控、可追溯。
层级名称 |
层级核心定位 |
数据结构 |
核心技术手段 |
适用场景 |
多模态原始贴源层(M-ODS 层) |
多模态数据的统一接入入口,全量原始数据的贴源存储与归档,是整个治理体系的数据源底座,不做深度加工,保留数据原始样貌 |
全量异构原始多模态数据,包括未处理的原始文本、原生图片 / 音频 / 视频、原始业务文档、数据库原始结构化表、网页爬取原始数据等,格式异构、来源分散、无标准化处理,保留原始元数据与接入链路 |
多源异构数据统一接入、多格式兼容性校验、原始元数据自动采集、全量数据归档备份、接入链路全流程审计、原始数据加密存储 |
原始数据合规溯源、全量数据备份归档、后续治理加工的源头数据源、原始数据合规性审计, 不可直接用于大模型训练 / 推理 |
多模态清洗明细层(M-DWD 层) |
经过基础清洗治理的单模态明细数据层,解决原始数据脏、乱、差、重的问题,完成单模态数据的标准化、干净化处理,是多模态治理的基础核心层 |
清洗标准化后的 单模态明细数据 ,包括去重去噪后的纯文本数据、过滤后的合规图片数据、去噪转写后的音频明细数据、抽帧解析后的视频明细数据、结构化转语义后的业务明细数据;单模态独立、粒度最细、无跨模态聚合融合,数据格式统一、噪声已剔除 |
精准去重 / 语义近重去重、低质数据过滤、噪声剔除、格式标准化、基础敏感信息脱敏、OCR/ASR/ 文档结构化解析、基础内容安全审核、无效数据剔除、语种规范化处理 |
预训练语料基础素材库、单模态数据统计分析、跨模态融合加工的基础数据源、批量语义特征提取、单模态内容检索 |
多模态融合整合层(M-DWS 层) |
跨模态语义融合与对齐的核心整合层,是多模态数据治理区别于传统数仓的核心层级,解决跨模态语义不匹配、信息孤岛问题,完成跨模态数据的语义统一表征与关联对齐 |
跨模态融合对齐数据,包括图文配对对齐数据、音视频 - 字幕文本对齐数据、多模态语义关联数据集、知识图谱关联融合数据、业务结构化数据与文本语义融合数据;核心特征是跨模态语义统一、关联关系明确、一致性经过校验 |
多模态 Embedding 向量化、跨模态语义对齐校验、图文 / 音视频一致性核验、语义关联映射、知识图谱融合构建、结构化数据语义化转换、跨模态血缘关联、全局统一语义编码 |
多模态大模型预训练、跨模态对齐微调、多模态知识图谱构建、企业级统一语义中台、跨模态内容检索、全局语义分析 |
多模态场景化数据集层(M-ADS 层) |
面向大模型全生命周期场景的定制化数据集层,针对模型训练 / 推理场景做定向加工,是可直接输入大模型使用的标准化数据集,完成从 “可用数据” 到 “场景化可用数据” 的转化 |
场景化定制数据集,包括通用预训练语料数据集、SFT 监督微调指令数据集、RLHF/DPO 偏好对齐数据集、RAG 知识库切片数据集、多模态指令微调配对数据集、领域小样本训练数据集;按场景完成格式化、切片、标注,可直接适配模型输入要求 |
指令格式化处理、知识切片与窗口优化、批量向量化索引构建、数据标注 / 专业领域标注、数据集拆分(训练 / 验证 / 测试集)、数据合成与增强、领域知识蒸馏、样本均衡化处理 |
大模型继续预训练、监督微调(SFT)、人类偏好对齐(RLHF/DPO)、RAG 检索增强知识库、领域模型适配微调、小样本 / 零样本学习、模型效果测评 |
多模态高质量资产层(M-DAM 层) |
经过模型效果验证、全链路合规审计的最高质量多模态数据资产层,是企业可复用、可管控、可溯源的核心数据资产,完成从 “场景化数据集” 到 “高价值核心资产” 的升级 |
经过模型闭环验证的 高质量黄金数据集 ,包括企业核心知识资产库、合规审计通过的标杆数据集、模型价值观对齐安全样本库、分级分类的可复用领域资产库;核心特征是质量经过模型效果验证、全链路合规可追溯、资产价值可量化 |
大模型多维度质量打分、模型效果归因分析、治理策略闭环迭代优化、全维度合规审计、数据资产分级分类、全链路血缘追踪、资产价值评估、安全加密与授权管控 |
核心大模型预训练、标杆级领域微调任务、企业级核心 RAG 知识库、模型安全与价值观对齐、对外合规数据资产输出、监管合规审计备案 |
7. 数据工作
划分“采集-预处理-标注-合规-交付-资产运营”6大工作分组,共39项具体工作任务。采集组解决多源数据汇聚问题,预处理组聚焦格式标准化与去重清洗,标注组实现数据语义增强,合规组构建全流程审计机制,交付组输出场景化数据集,资产运营组完成数据资产化管理,每个分组的工作内容均对应治理流程的关键环节,确保治理工作可落地、可分工、可考核,避免体系建设与执行脱节。
分组名称 |
核心工作内容 |
适用场景 |
数据采集与汇聚组 |
1. 多源多模态数据合规采集,覆盖公开网页、行业数据库、企业私域数据、授权第三方数据源等全渠道 |
通用预训练语料库原始素材建设、企业私域知识库原始素材汇聚、微调数据集原始素材采集、全量数据合规归档与溯源、增量数据常态化同步 |
2. 全量原始数据的统一汇聚、归档备份,完整保留数据原始链路、授权文件与原生元数据 |
3. 数据接入的格式兼容性校验、原始数据完整性校验、无效数据源剔除 |
4. 全量数据源台账维护、采集链路合规审计、数据源授权全生命周期管理 |
5. 增量数据的定时同步、批次管理、全链路采集日志留痕 |
数据预处理与清洗组 |
1. 多模态数据格式标准化与格式转换,包括音视频转码、文档格式统一、图片分辨率标准化、编码格式统一 |
预训练语料库基础清洗加工、RAG 知识库原始素材预处理、单模态明细数据资产建设、微调数据集基础标准化、多模态数据基础解析入库 |
2. 全量数据去重处理,包括精准去重、语义近重识别与剔除、重复片段 / 重复文件批量处理 |
3. 低质 / 无效 / 噪声数据过滤,包括垃圾文本、模糊图片、无意义音视频、空白 / 损坏文档、乱码数据批量剔除 |
4. 非结构化数据基础解析,包括 OCR 图文识别、ASR 语音转写、视频关键帧提取、文档结构化解析、代码语法格式化 |
5. 基础噪声剔除、语种规范化、特殊字符 / 冗余内容处理、基础敏感信息初筛与标记 |
核心数据治理组 |
1. 多模态数据语义深度治理,包括事实一致性校验、知识密度分级、内容质量多维度打分、虚假信息识别与剔除 |
多模态预训练语料库深度治理、企业级 RAG 知识库建设、跨模态对齐数据集加工、领域知识图谱构建、多模态语义中台建设、高质量明细数据资产生产 |
2. 跨模态数据语义对齐,包括图文 / 音视频内容一致性核验、跨模态语义关联映射、全局统一语义编码 |
3. 数据分类分级、领域标签体系建设、知识体系梳理、业务语义标准化 |
4. 知识切片、语义分块、窗口优化,适配大模型上下文窗口与输入要求 |
5. 全流程数据质量管理,包括质量规则制定、批量质量稽核、质量问题溯源与整改、质量报告输出 |
6. 结构化数据语义化转换、知识图谱构建与融合、多模态 Embedding 向量化、向量索引构建与优化 |
数据标注与增强组 |
1. 通用基础标注:文本分类、实体标注、意图识别、图文配对标注、音视频内容分段标注、场景标签标注 |
SFT 监督微调数据集制作、RLHF/DPO 偏好对齐数据集建设、领域大模型微调、小样本 / 零样本学习数据集制作、模型安全对齐训练、多模态指令跟随能力训练 |
2. 专业领域标注:行业知识标注、专业术语标注、指令 - 回答配对标注、专业内容事实校验标注(联合行业专家完成) |
3. 大模型对齐标注:RLHF/DPO 偏好排序标注、人类反馈数据标注、有害内容识别标注、模型价值观对齐标注 |
4. 标注全流程管控:标注规则制定、标注流程标准化、标注质量抽检与校验、标注人员培训与管理 |
5. 数据合成与增强:高质量样本合成、领域数据增强、小样本场景数据扩充、指令模板优化与扩充、样本均衡化处理 |
元数据与资产运营组 |
1. 多模态元数据全生命周期管理,包括元数据自动采集、更新、维护、检索与标准化管理 |
企业级多模态数据资产平台建设、全量数据合规溯源、预训练 / 微调数据集版本管理、RAG 知识库全生命周期运维、数据资产复用与共享、企业数据资产化落地 |
2. 数据 - 模型全链路血缘追踪、血缘图谱构建、可视化溯源、数据变更全流程留痕 |
3. 多模态数据资产分级分类、资产目录建设、资产编目、资产检索与共享管理 |
4. 数据资产版本管理、增量更新管控、数据集全生命周期版本追溯 |
5. 数据资产价值评估、资产运营台账维护、资产授权与订阅管理、资产复用率提升 |
6. 数据全生命周期管理,包括数据归档、销毁、留存周期管控,符合监管与业务要求 |
安全合规与审计组 |
1. 多模态数据全链路内容安全审核,有害 / 低俗 / 违规 / 敏感内容识别与批量剔除 |
预训练语料库全维度合规审核、微调数据集安全校验、RAG 知识库合规管控、模型安全对齐训练、监管合规审计备案、AIGC 生成内容全链路安全管控 |
2. 全模态敏感信息识别与脱敏,包括个人信息、商业秘密、涉密内容的自动化识别与脱敏处理 |
3. 版权合规全流程管控,包括版权溯源、侵权内容识别、数据源授权管理、商用内容合规性校验 |
4. 数据偏见、歧视性内容识别与治理、模型价值观对齐合规管控、越狱风险数据筛查与剔除 |
5. 全流程合规审计留痕、合规台账维护、监管合规对接、风险事件处置与复盘 |
6. 数据安全分级、细粒度权限管控、数据加密存储、数据跨境合规管控 |
场景化数据交付组 |
1. 面向预训练场景的语料库封装、批次划分、模型格式适配、交付与验收、交付台账维护 |
大模型预训练语料交付、监督微调 / 偏好对齐数据集交付、企业 RAG 知识库交付、模型测评数据集交付、领域大模型定制化数据集开发、场景化数据解决方案落地 |
2. 面向微调场景的数据集标准化拆分(训练 / 验证 / 测试集)、格式化封装、场景适配定制、交付与效果初测 |
3. 面向 RAG 场景的知识库切片封装、向量索引交付、知识库更新迭代、运维支持与效果优化 |
4. 交付数据的模型适配性验证、效果测试、用户反馈收集、定向优化与迭代 |
5. 场景化数据解决方案制定、定制化数据集开发、交付版本全生命周期管理 |
6. 数据封装、加密交付、授权管控、交付文档与使用说明输出 |
8.类比数仓架构图